# graphql - 入门
# 什么是API
如果问上学的时候的我,我会说 API 就是 Application programming interface,这个时候HR就会不懂装懂地点点头然后让我进入下一轮面试。 如果问刚刚工作的我,我会说 API 就是接口嘛!PM灵光一现想出了一个新功能,我花几天时间写一个 API,把这个功能体现出来,前端做网页做APP的人可以用。 API 可以从封装方式来区分。主要是两个流派,一派是基于 REST,一派是基于 RPC。REST 是用 HTTP 封装,而 RPS 往往用自定义的协议封装。今天 REST 这一派衍生出了 GraphQL,而 RPC 这一派衍生出了 gRPC。这四种到底该用哪种,是今天互联网公司的日常争论。最后往往要吵到最核心的API定义:API到底是用来干什么的。
API 的本质就是帮人读数据、写数据。
# GraphQL
有几个特点:
- 不需要GET、POST、PUT、DELETE这么多动作,一切简化为读和写
- Response 不会一次给全部数据,用的时候要什么,服务器就返回什么
- PostBody 可以加入 variable
- 写 API 之前先写 Schema,一切数据都得定义类型
- 数据 Dependency 必须确立好,这样 Resource 结构一目了然
# Schema & Type
- GraphQL 有自己的简单语言
GraphQL schema language,来定义字段类型(Type)、数据结构、接口数据请求的规则; Type!表示非空(non-nullable);[Type]表示返回对应类型的数组;[Type]!表示非空数组;[Type!]!表示非空数组,内容也非空;
type Message {
id: String
content: String!
author: String!
length: Int
}
2
3
4
5
6
- Root Schema
schema {
query: Query
mutation: Mutation
}
2
3
4
- GraphQL 基本上是一棵树(tree),标量(scalar)类型是叶子节点(leave node);
- GraphQL 提供了一组开箱即用的默认标量类型:
- Int: 有符号32位整数.
- Float: 有符号双精度浮点数.
- String: UTF-8字符序列.
- Boolean: 布尔值.
- ID: 表示唯一的标识符,通常用于重新获取对象或用作缓存的键。ID 类型的序列化方法与 String 相同。但是,将其定义为 ID 表示它并不需要 human‐readable。
- 也可以自定义标量类型。例如,定义一个 Date 类型:
scalar Date
- 枚举类型是一种特殊的标量,它限制在一个特殊的可选值集合内,定义枚举类型:
enum Name {
ZhangSan
LiSi
WangErMaZi
}
2
3
4
5
- 接口(Interface)是一种抽象类型,它定义了一个类型必须包含的某些字段(Field);
interface Person {
id: ID!
name: String!
}
2
3
4
- 联合(Union)类型基本上是或(OR)逻辑;
- 注意,联合类型的成员需要是具体对象类型;
- 你不能使用接口或者其他联合类型来创造一个联合类型;
- 使用联合类型的时候要实现
resolveType函数来处理__typename;
union SearchResult = Human | Droid | Starship
- 输入(Input)对象看上去和常规对象一模一样,除了关键字是 input 而不是 type。更新数据时使用;
input PersonInput {
age: Int
name: String!
}
2
3
4
- 不能在 schema 中混淆输入和输出类型;
- 类型系统(Type System)可以帮助 API 服务做类型检查;
# Query & Mutation
- 查询(Query) 和变更(Mutation) 是 GraphQL 的两大支柱;
- Query 和 Mutation 也都是对象(Object)。 GraphQL 是面向对象编程(object-oriented-programming);
type Query {
getMessage(id: ID!): Message
}
type Mutation {
createMessage(input: MessageInput): Message
}
2
3
4
5
6
- GraphQL 始终返回 JSON 对象;
- GraphQL error 也是返回 200;
- 参数(Arguments)每个字段和嵌套对象都能有自己的一组参数;
query {
getMessage(id: "486") {
content
}
}
2
3
4
5
- 片段(Fragment)用来组织一组字段,方便复用;
fragment basicMessage on Message {
content
author
}
query {
getMessage(id: "486") {
... basicMessage
}
}
2
3
4
5
6
7
8
9
- 变量(Variable)使用动态值替换查询中的静态参数;
# variable {"id":"486"}
query ($id: ID!){
getMessage(id:$id) {
content
}
}
2
3
4
5
6
- 片段(Fragment) 和变量(Variable)可以显著优化查询操作,只选择需要的字段(Field)可以提升性能;
- 操作名称(Operation name),就像 Function name,匿名函数并不影响使用,但是加上名字可以方便追踪调试;
- 指令(Directives)可以使用变量动态的改变查询结构:
@include(if: Boolean)仅在参数为 true 时,包含此字段。@skip(if: Boolean)如果参数为 true,跳过此字段。
# {"idx":"486", "withAuthor": false }
query GetMessage ($idx: ID!, $withAuthor: Boolean!) {
getMessage(id: $idx ) {
content
author @include(if: $withAuthor)
}
}
2
3
4
5
6
7
- 查询操作是并行执行的,变更操作是依次执行的(这是为了防止竞争条件(Race Condition));
- 可以使用
__typename来获取元字段,允许在查询的任何位置使用,以获得对象的类型名称。区分联合类型的时候有用; - 使用
__type来查询 Schema;
{
__type(name:"Mutation") {
name
fields {
name
type{
name
}
args{
name
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# Subscription
- GraphQL 还可以进行数据订阅,当前端发起订阅请求之后,如果后端发现数据改变,可以给前端推送实时信息。
# Schema 定义:
type Subscription {
subCreateMessage: Message
}
# 请求
subscription {
subCreateMessage {
id
}
}
2
3
4
5
6
7
8
9
10
11
Response:
{
"subCreateMessage": {
"id": "486"
}
}
2
3
4
5
node 服务端配置:
const express = require('express');
const { graphqlHTTP } = require('express-graphql');
const { SubscriptionServer } = require('subscriptions-transport-ws');
const PORT = 4000;
const app = express();
app.use('/graphql', graphqlHTTP({
schema,
rootValue: root,
graphiql: { subscriptionEndpoint: `ws://localhost:${PORT}/subscriptions` },
}));
const ws = createServer(app);
ws.listen(PORT, () => {
console.log(`Running a GraphQL API server at localhost:${PORT}/graphql`);
// Set up the WebSocket for handling GraphQL subscriptions.
new SubscriptionServer(
{
execute,
subscribe,
schema,
rootValue: root
},
{
server: ws,
path: '/subscriptions',
},
);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# Validation
I think when they invented GraphQL, they want to call it TreeQL, but then realized that object relationship can be pointing backward, like a graph. So TreeQL becomes GraphQL.
- 查询规则:
- 只能查询给定类型上的字段;
- 返回值不是标量或者枚举型,需要指明要从字段中获取的数据;(i.e. 始终以叶子节点结尾)
- 片段不能引用其自身或者创造回环,因为这会导致结果无边界;
这个查询是有效的:
{
hero {
...NameAndAppearances
friends {
...NameAndAppearances
friends {
...NameAndAppearances
}
}
}
}
fragment NameAndAppearances on Character {
name
appearsIn
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
无效查询:
fragment NameAndAppearancesAndFriends on Character {
name
appearsIn
friends {
...NameAndAppearancesAndFriends
}
}
2
3
4
5
6
7
# Execution
- 每个类型的每个字段都由一个 resolver 函数支持,该函数产生下一个值。如果字段产生标量值,例如字符串或数字,则执行完成。如果一个字段产生一个对象,则该查询将继续执行该对象对应字段的解析器,直到生成标量值。GraphQL 查询始终以标量值结束(完美 OOP)。
- 这是一个 js 的 resolver 例子:
Query: {
human(obj, args, context, info) {
return context.db.loadHumanByID(args.id).then(
userData => new Human(userData)
)
}
}
2
3
4
5
6
7
因为从数据库拉取数据的过程是一个异步操作,该方法返回了一个 Promise 对象。解析器能感知到 Promise 的进度,在获取到数据后,由于类型系统确定了 human 字段将返回一个 Human 对象,GraphQL 会根据类型系统预设好的 Human 类型决定如何解析字段。
# Introspection
如果是我们亲自设计了类型,那我们自然知道哪些类型是可用的。但如果类型不是我们设计的,我们也可以使用 GraphQL 的内省系统,通过查询 __schema 字段来向 GraphQL 询问哪些类型是可用的。 假如定义为:
type Message {
id: String
content: String!
author: String!
length: Int
}
input MessageInput {
content: String!
author: String!
}
type Query {
getMessage(id: ID!): Message
getAllMessage: [Message]
}
type Mutation {
createMessage(input: MessageInput): Message
updateMessage(id: ID!, input: MessageInput): Message
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
{
__schema {
types {
name
}
}
}
2
3
4
5
6
7
Response:
{
"data": {
"__schema": {
"types": [
{
"name": "Message"
},
{
"name": "MessageInput"
},
{
"name": "String"
},
{
"name": "ID"
},
{
"name": "Int"
},
{
"name": "Query"
},
{
"name": "Mutation"
},
{
"name": "Boolean"
},
{
"name": "__Schema"
},
{
"name": "__Type"
},
{
"name": "__TypeKind"
},
{
"name": "__Field"
},
{
"name": "__InputValue"
},
{
"name": "__EnumValue"
},
{
"name": "__Directive"
},
{
"name": "__DirectiveLocation"
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
返回的类型主要包括:
- Query, Mutation, Message, MessageInput : 这些是我们在类型系统中定义的类型;
- String, Boolean : 这些是内建的标量,由类型系统提供;
- __Schema, __Type, __TypeKind, __Field, __InputValue, __EnumValue, __Directive : 这些有着两个下划线的类型是内省系统的一部分;
继续查询 Query:
{
__type(name:"Query") {
name
kind
fields {
name
type {
kind
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
Response:
{
"data": {
"__type": {
"name": "Query",
"kind": "OBJECT",
"fields": [
{
"name": "getMessage",
"type": {
"kind": "OBJECT"
}
},
{
"name": "getAllMessage",
"type": {
"kind": "LIST"
}
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
Query 是一个 OBJECT,有两个字段 getMessage 和 getAllMessage
# Best practice
- HTTP
Good: 通过单入口来提供 HTTP 服务的完整功能(Query & Mutation); Bad: 通过暴露一组 URL 且每个 URL 只暴露一个资源; (虽然 GraphQL 也可以暴露多个资源 URL 来使用,但这可能导致在使用 GraphiQL (opens new window) 等工具时遇到困难。)
JSON:使用 JSON 并开启 GZIP 压缩,
Accept-Encoding: gzip空:在 GraphQL 类型系统中,默认情况下每个字段都
可以为空。用来避免各种异常情况下请求完全失败;GraphQL 服务可能会像"聊天"一样反复从您的数据库加载数据, 考虑通过批处理和缓存来优化性能;
应该在哪里定义真正的业务逻辑?应该在哪里验证,检查用户权限?就是在专门的业务逻辑层里。业务逻辑层应作为执行业务域规则的唯一正确来源。
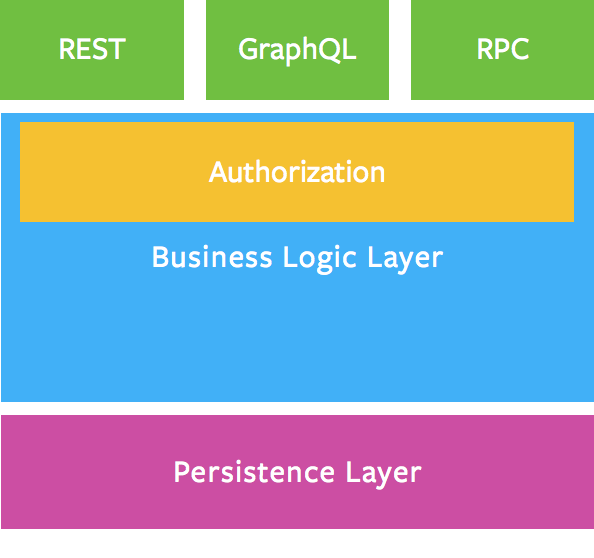
- GraphQL 仅使用 GET 和 POST:
- 对于 GET, 接受
?query=...&variables=...&operationName=... - 对于 POST,使用
Content-Type:application/json请求体:
- 对于 GET, 接受
{
"query": "...",
"operationName": "...",
"variables": { "myVariable": "someValue"}
}
2
3
4
5
响应:
# 正确返回
{
"data": { ... }
}
# 错误返回
{
"errors": [ ... ]
}
2
3
4
5
6
7
8
如果没有返回错误,响应中不应当出现 "errors" 字段。如果没有返回数据,则 根据 GraphQL 规范 (opens new window),只能在执行期间发生错误时才能包含 "data" 字段。
- 生产环境需要禁用 GraphiQL;
app.use('/graphql', graphqlHTTP({
schema: MySessionAwareGraphQLSchema,
graphiql: process.env.NODE_ENV === 'development',
}));
2
3
4
对于分页,基于游标的分页是最强大的分页,建议用 base64 编码游标。
全局对象识别:一致的对象访问实现了简单的缓存和对象查找。 如果对象拥有全局唯一的ID,GraphQL schema 的格式允许通过根查询对象上的 node 字段获取任何对象。 如果 id 相同,则必须是同一对象。
# 具有全局唯一 ID 的对象
interface Node {
# 对象的 ID
id: ID!
}
type Message implements Node {
id: ID!
# 内容
content: String!
}
# 查询
query retrieveNodeById {
node(id: "4") {
id
... on Message {
content
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- 全局对象标识可以用来作为缓存的 key。 在过去通常使用
<url>:<response>这样的缓存 key,现在可以使用<object_id>:<object>。
参考